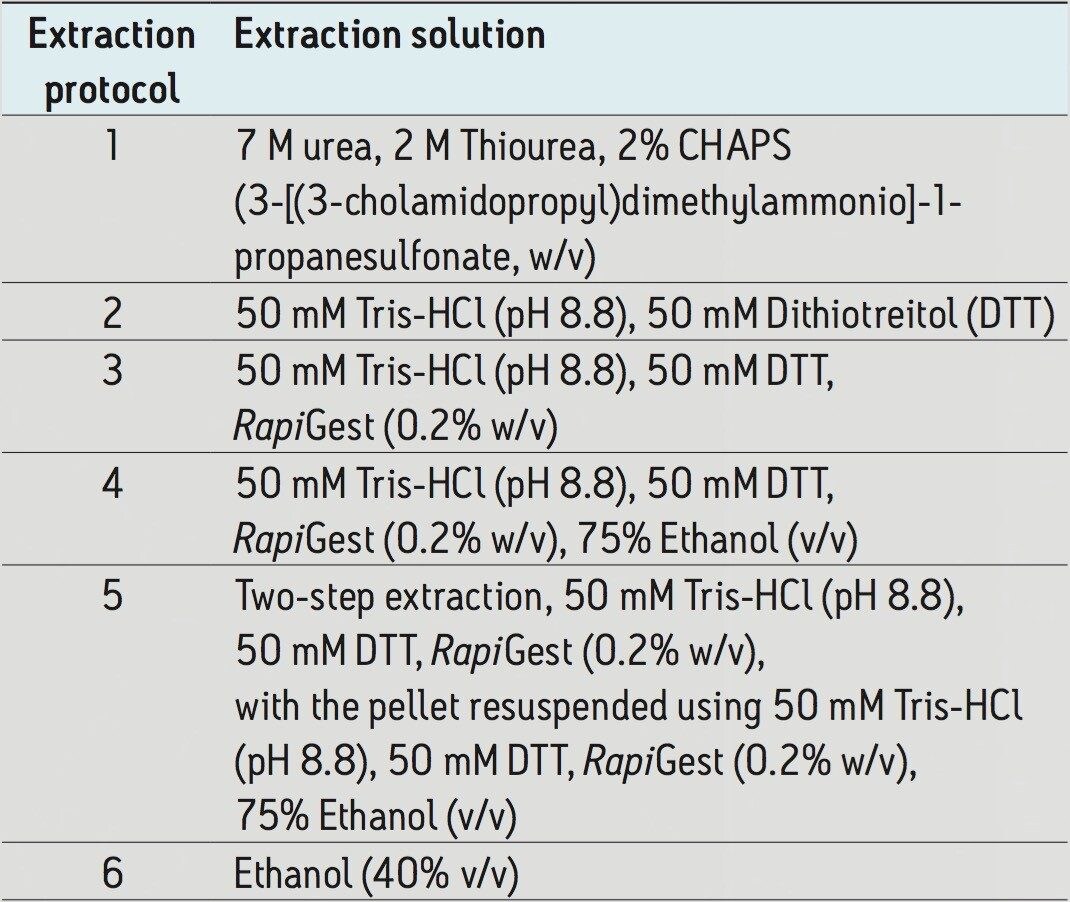
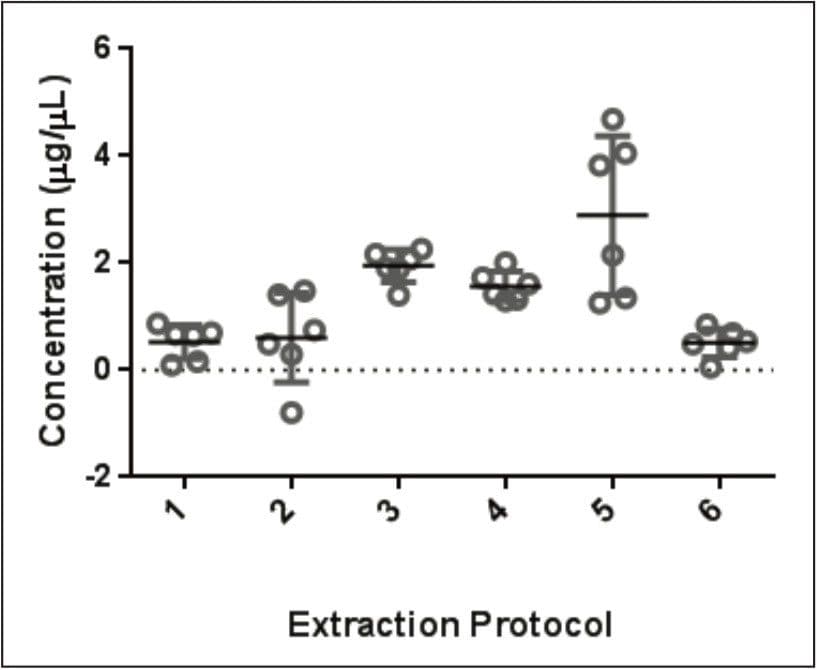
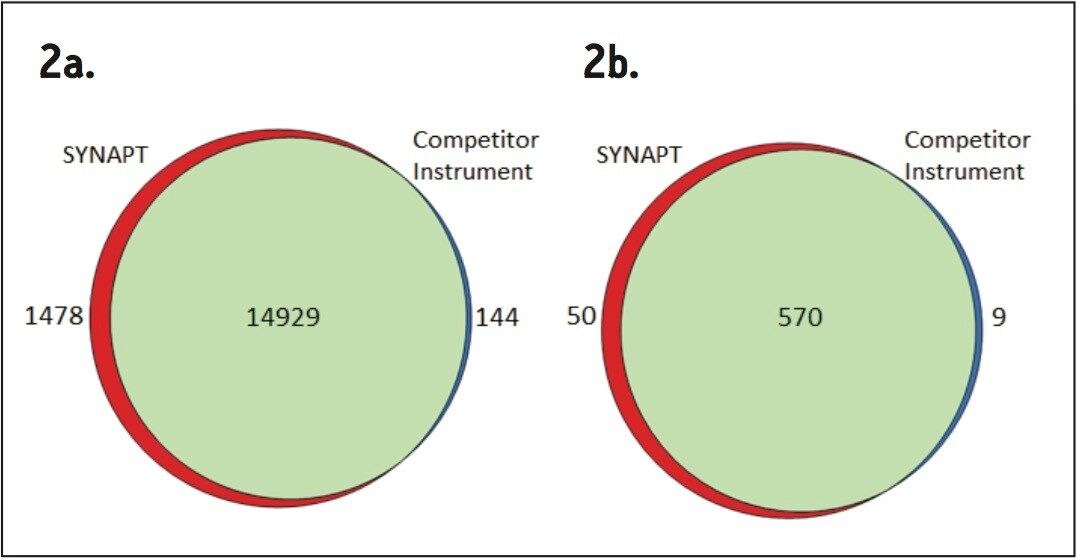
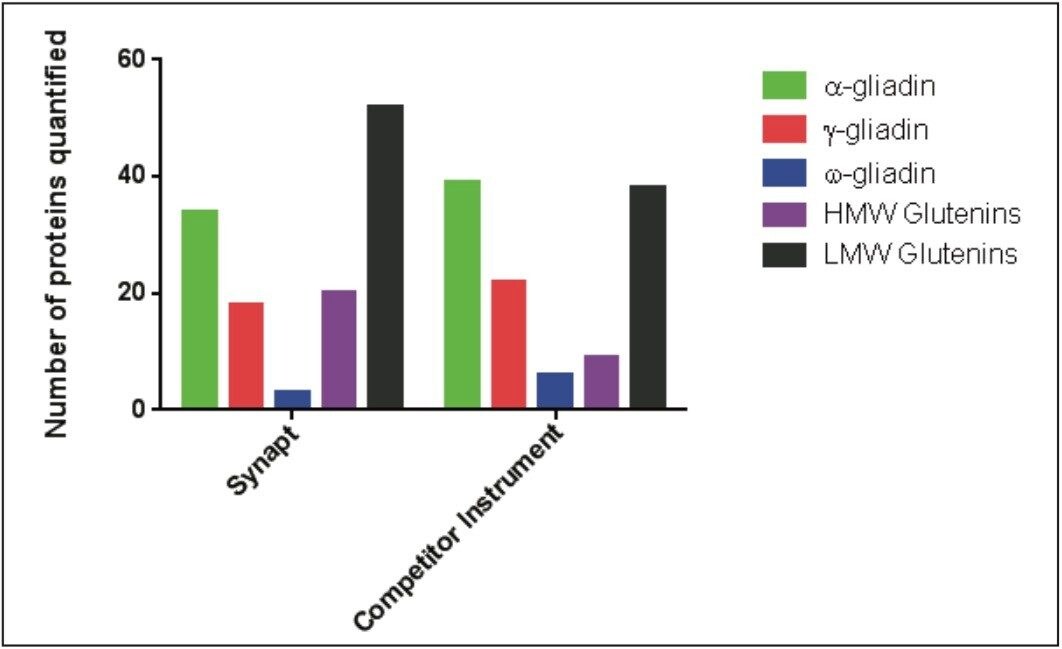
Wheat is the most widely grown food crop worldwide and forms a staple part of the modern diet.1 However, it poses a health risk to a small proportion of the population because it contains gluten – a protein fraction able to trigger celiac disease (CD).2 Celiac disease is a non-IgE immune mediated adverse reaction to gluten that affects about 70 million people globally.3 Gluten is formed from the major storage proteins of wheat grain and comprises two groups of proteins, which are classified based on their solubility in aqueous alcohol mixtures. The gliadins are alcohol-soluble while the glutenins are alcohol-insoluble, requiring reduction for solubilization due to their presence as high molecular mass aggregates stabilized by inter-chain disulphide bonds.4,5 The gliadin proteins can be further sub-grouped into α-, γ-, and ω-gliadins, which are differentiated by both the repetitive peptide motifs present in their sequences and in the number of cysteine residues. The glutenin proteins can be further classified into two groups: high molecular weight (HMW) and low molecular weight (LMW) subunits of glutenin, based on molecular weight. The different solubility properties of the gliadin and glutenin proteins make their simultaneous extraction, detection, and quantification problematic. Gluten proteins contain few, if any, lysine and arginine residues, resulting in poor digestion by trypsin. Therefore, an alternative protease – such as chymotrypsin – must be used to undertake the digestion step in proteomic workflows. The resulting digests comprise longer peptides, and their identification by means of mass spectrometry can be challenging. This study highlights improved gluten extraction efficiency using the acid labile detergent RapiGest followed by identification of the celiac toxic motif regions using a label-free LC-HDMSE (LC-DIA-IM-MS) approach.