Coffee is a chemically complex beverage, brewed from the roasted seeds of the berries (referred to as beans) most commonly from two plants of the Coffea genus: Coffea arabica (Arabica or Arabian coffee) and Coffea canephora (Robusta coffee). The two different species give rise to distinct variation in the taste and aroma of the drink. Further variations can be introduced by the fermentation, processing, roasting, grinding, brewing, and storage, which can make the distinction between the species more difficult to the consumer, and there are concerns that the cheaper Robusta may be fraudulently substituted for Arabica.
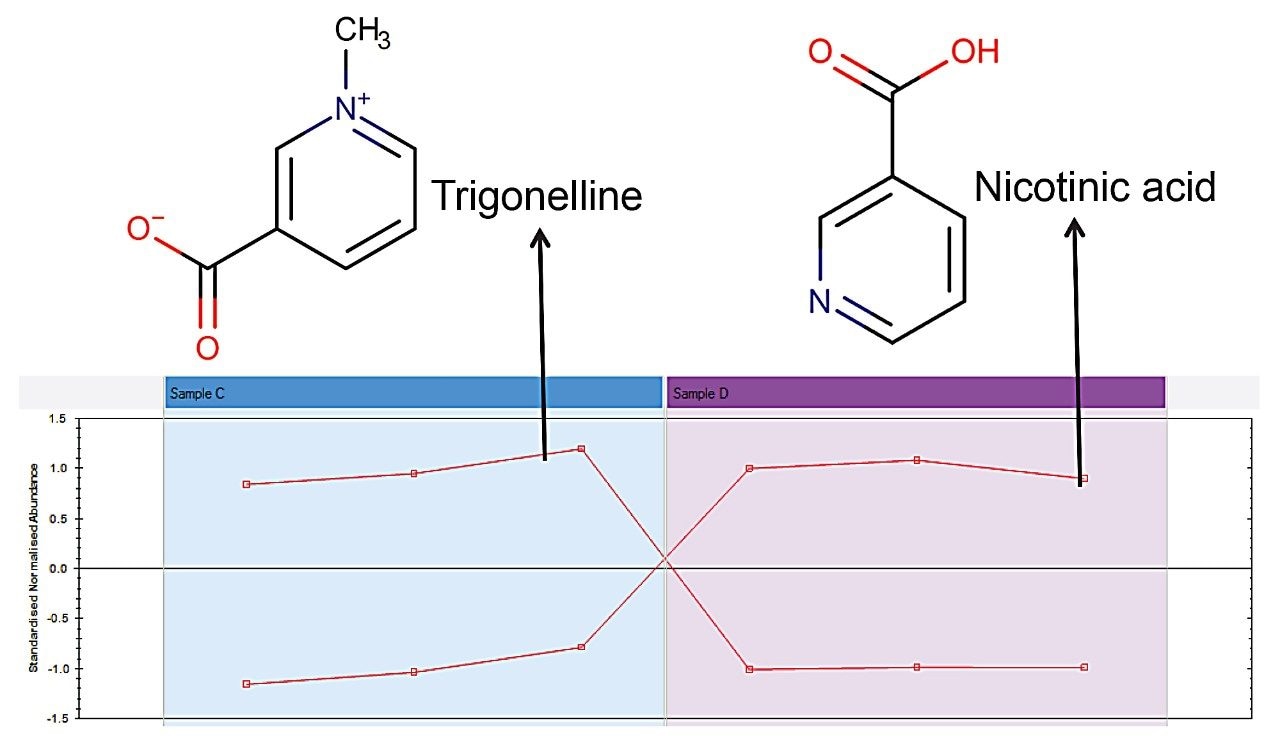
Much of the chemistry of the flavor and aroma compounds is understood, and attributed to compounds such as sucrose, furans, pyrazine, alkyl-pyridines, pyrroles, and of course caffeine. Related precursors/metabolites of these compounds that are seen as desirable include trigonelline and chlorogenic acid.
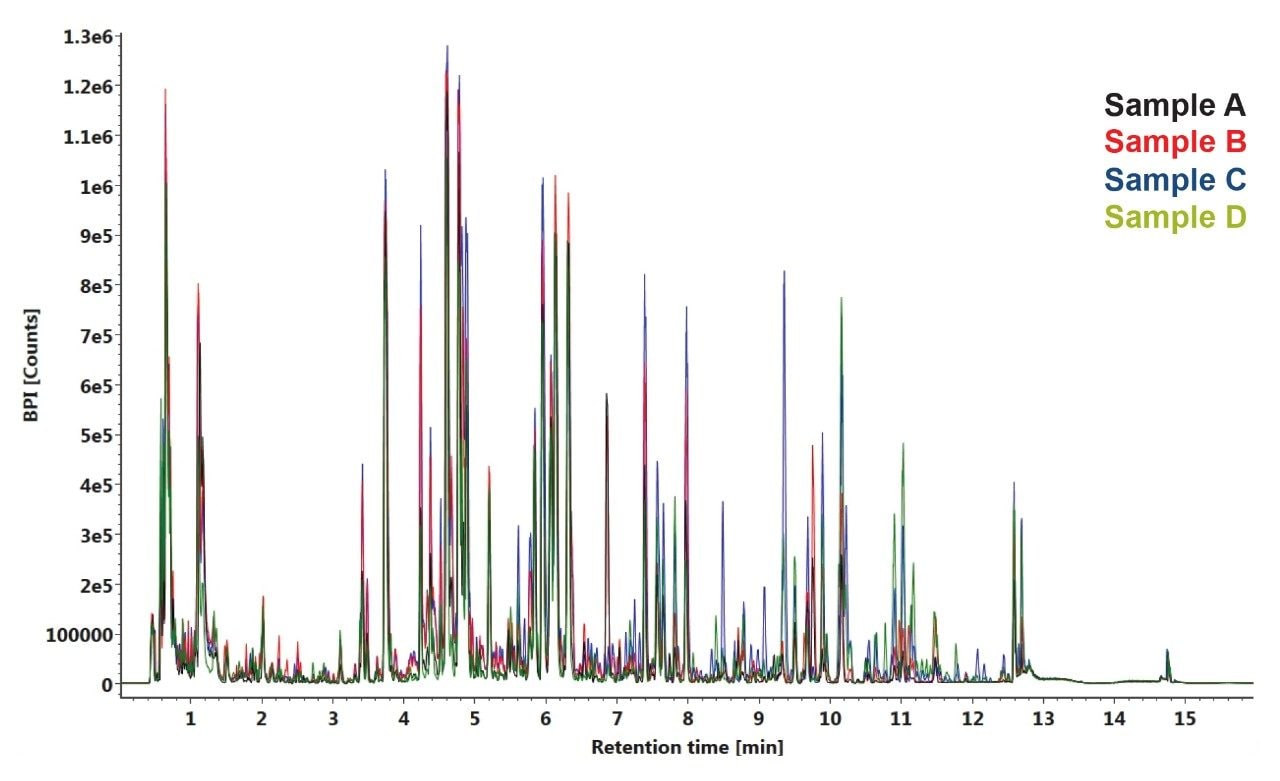
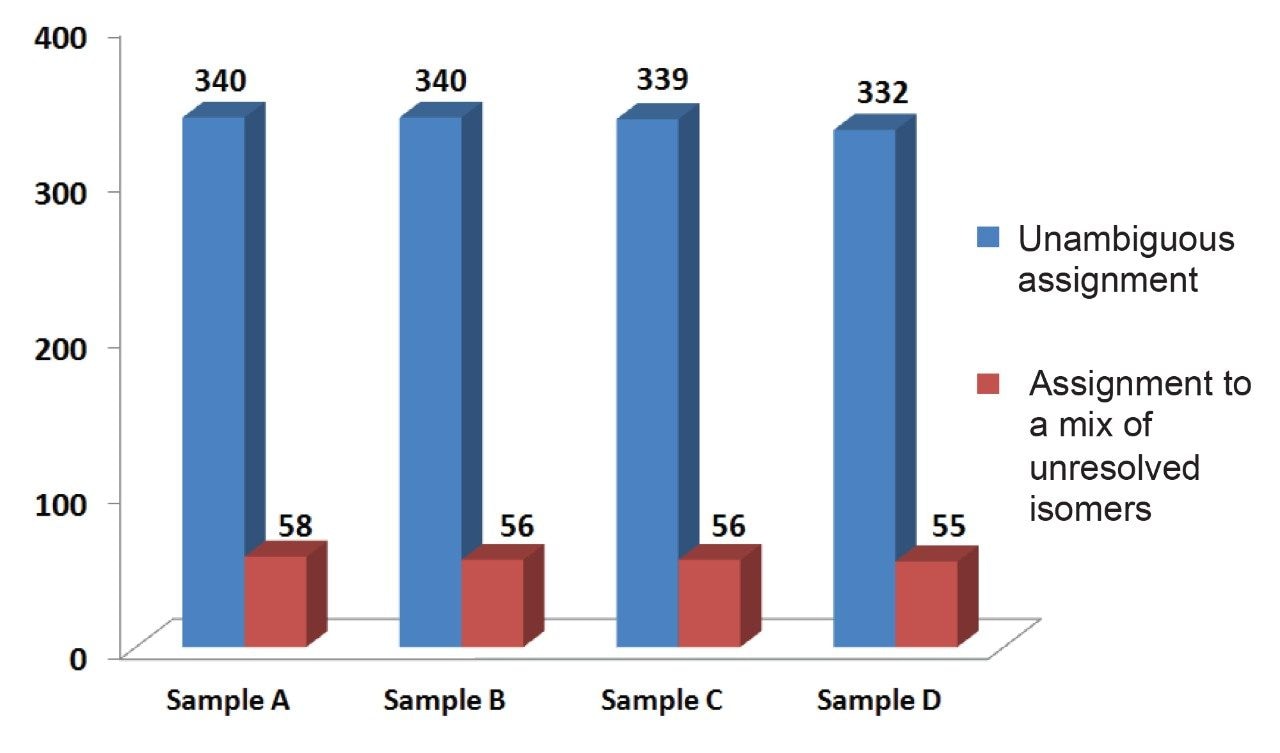
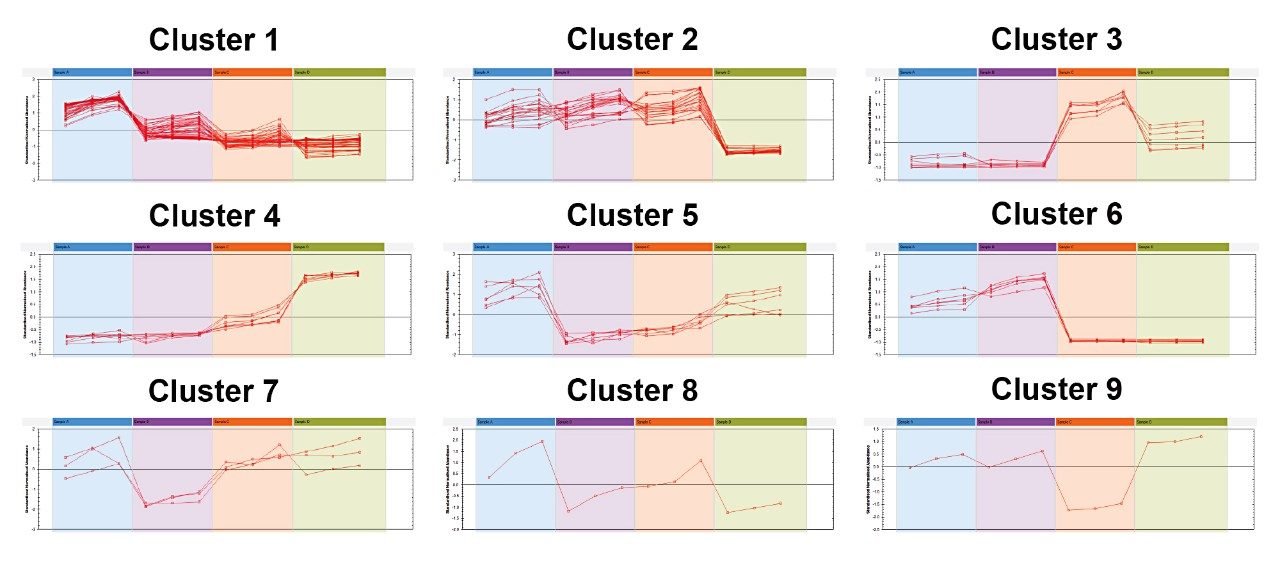
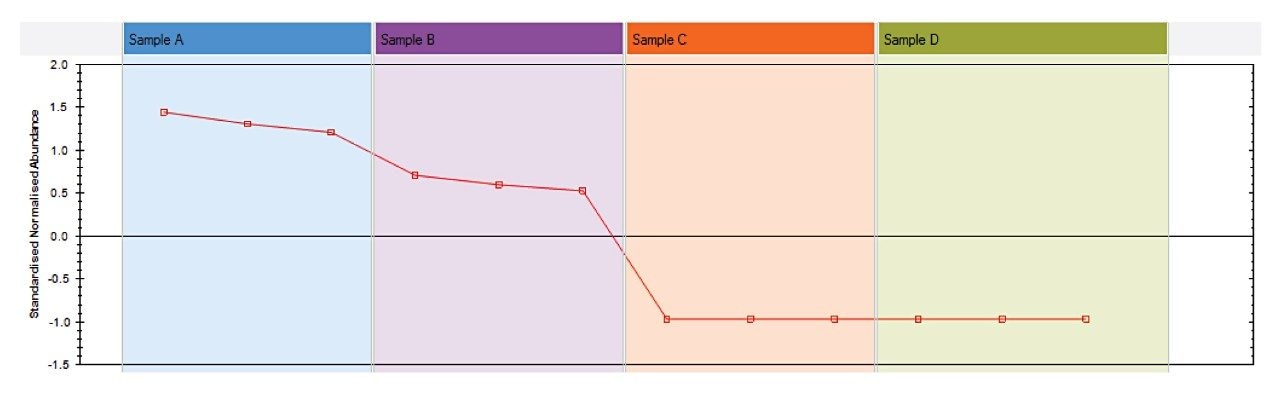
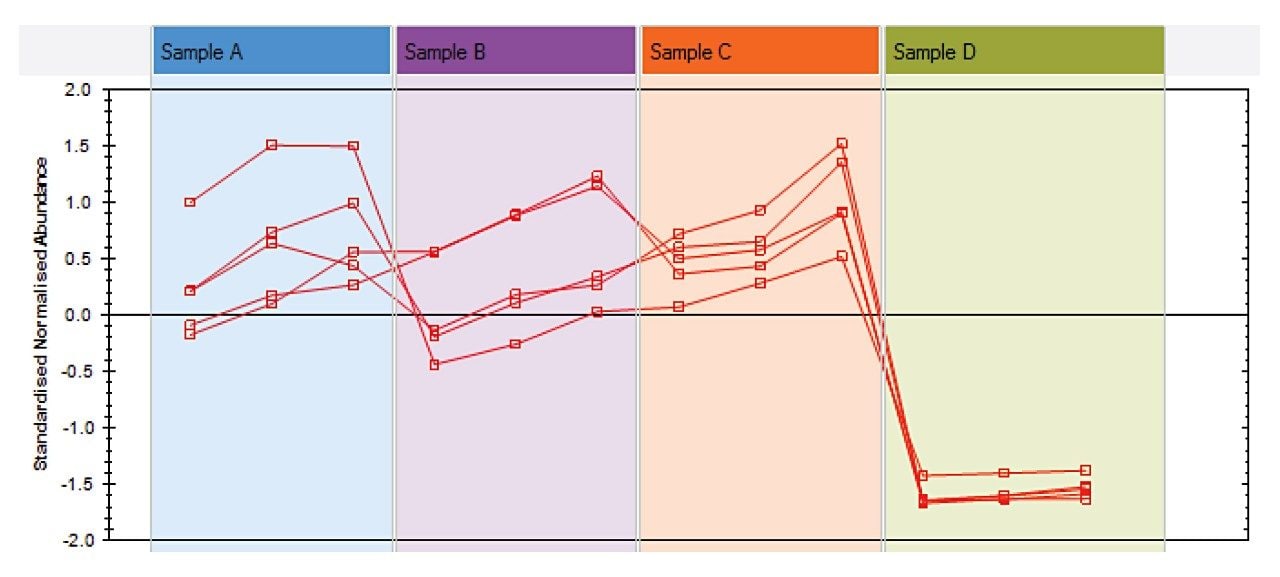
Providing chemical information on coffee brews can be used to assess the quality of a grind, process or species, or to further explore the taste and aroma chemistry. In this application note, samples of coffee brews were provided blind, in order to elucidate the origin and treatment of the beans.