Food fraud is a collective term which describes a substitution, addition, alteration; or a misrepresentation, deliberate and intentional of food ingredients or of food packaging; or false or misleading statements formulated concerning a product for economic gain.1 Recent scandals have highlighted that food fraud can also result in major food safety issues.
Honey is a high value food commodity frequently subjected to fraudulent mislabeling and adulteration. The non-compliances detected during the European Commission (EC) 2015 coordinated control plan were mostly related to adulteration with sugar (6%), and to the declaration of the botanical source (7%). Non-compliances related to the declaration of the geographical origin were less frequent (2%), but were considered more difficult to detect.2 Analytical methods used in the quality control of honey have recently been reviewed.3
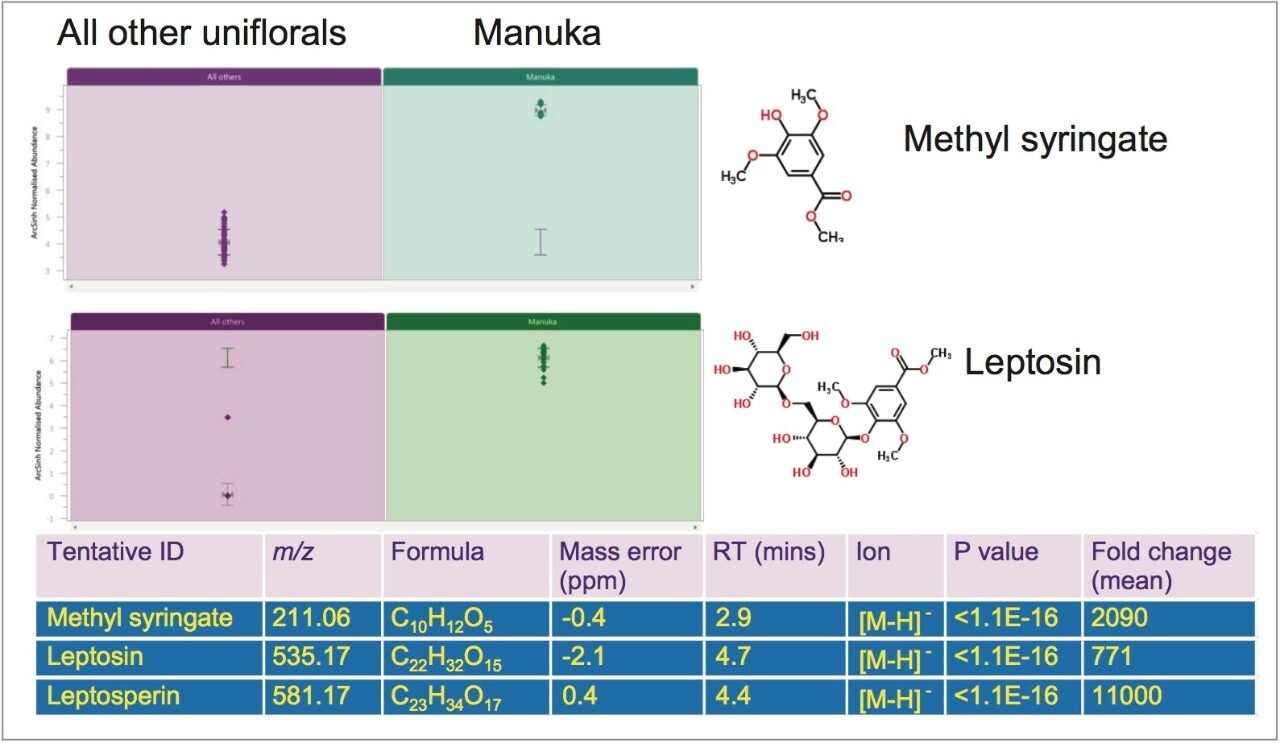
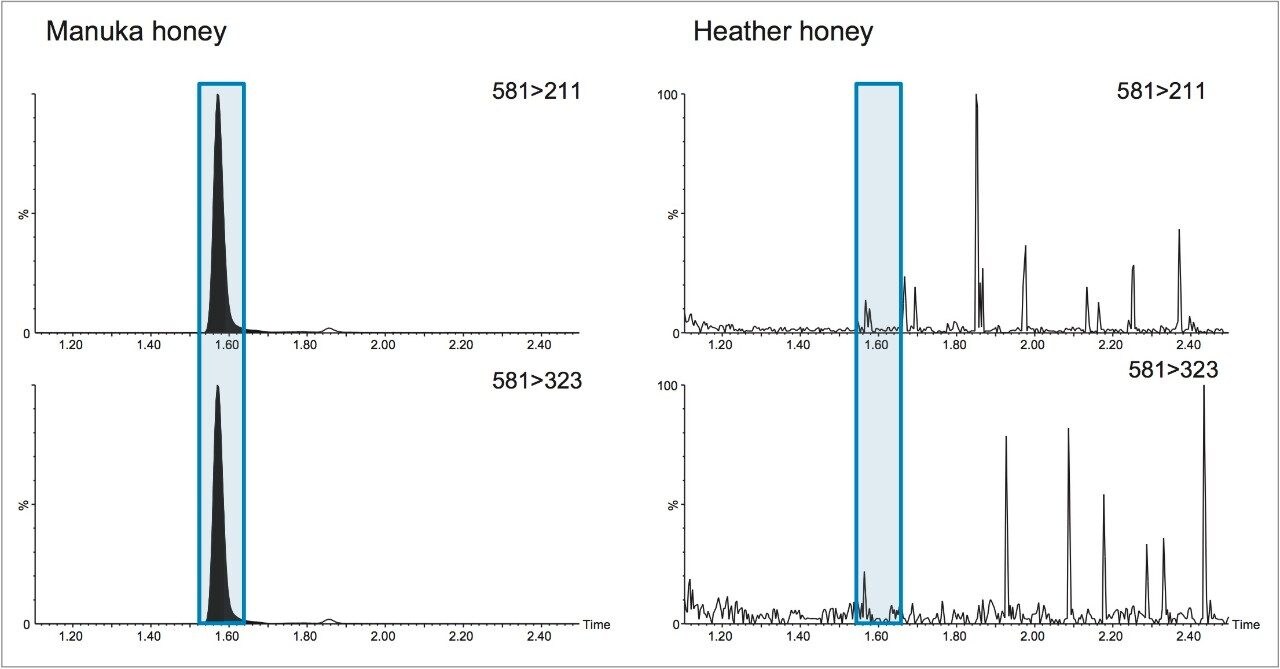
The nutraceutical properties of honey arise from specific chemical compositions, which vary according to botanical origin. These properties also confer distinct sensory profiles to various types of unifloral honeys. For these reasons, the price of unifloral honeys is higher than that of polyfloral honey. Adulteration in terms of the dilution of honeys of high value floral origin with those of lower value has increased in recent years. For example, the great commercial relevance attributed to Manuka honey, due to the promotion of its perceived increased antibacterial activity and health benefits, as well as its limited availability, has led to a high frequency of fraud. Guidance on labeling requirements and defining the characteristics of Manuka honey has been established.4
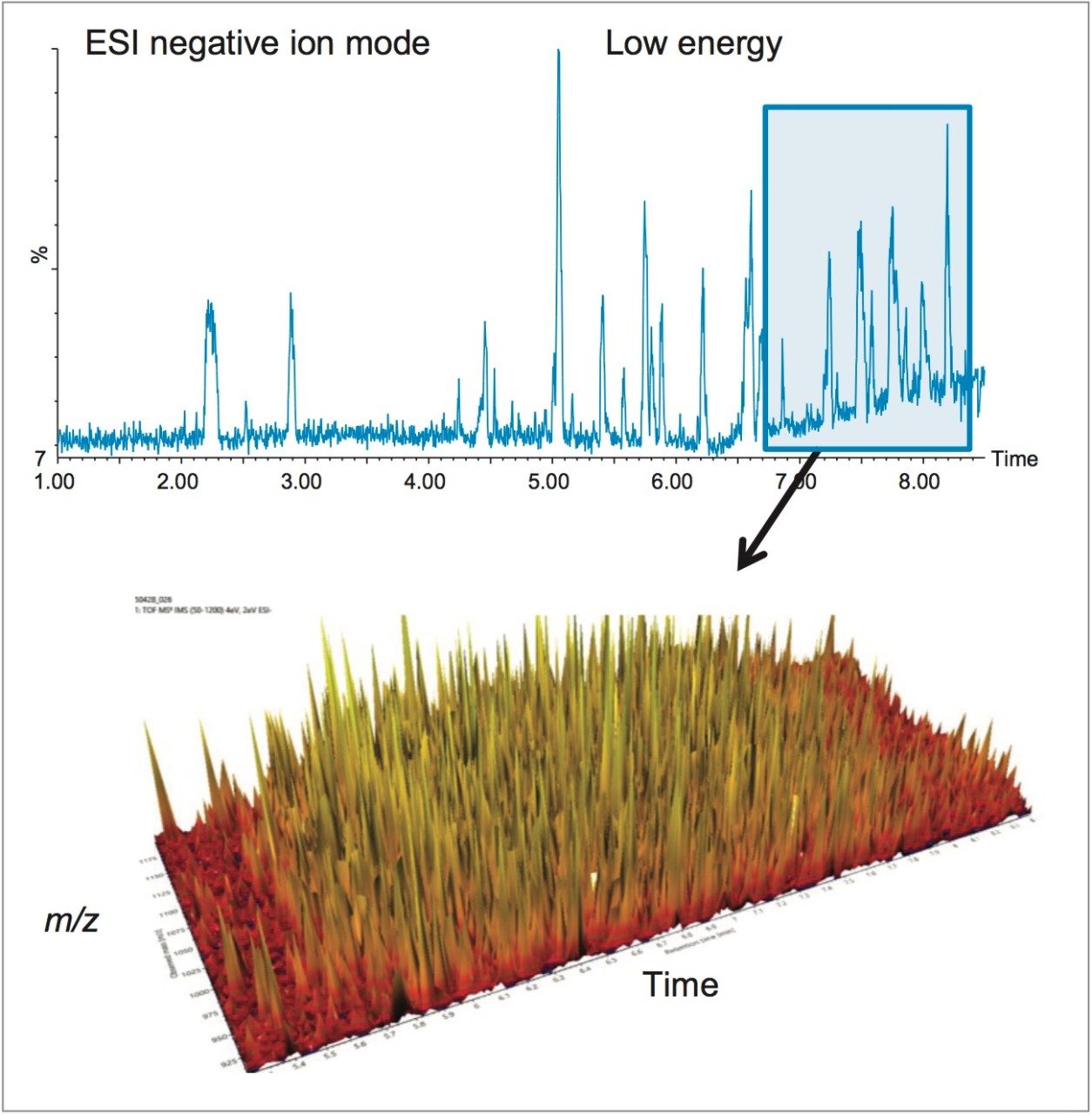
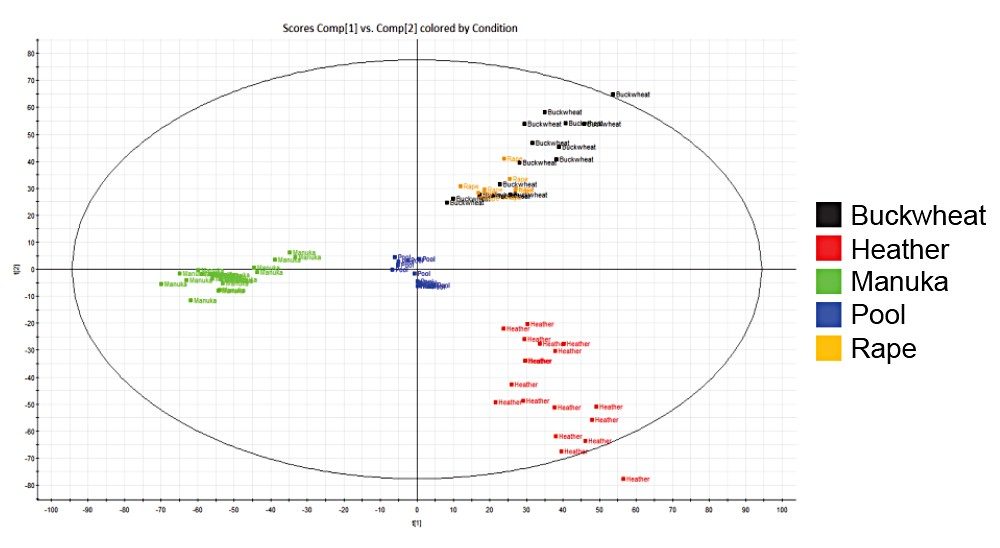
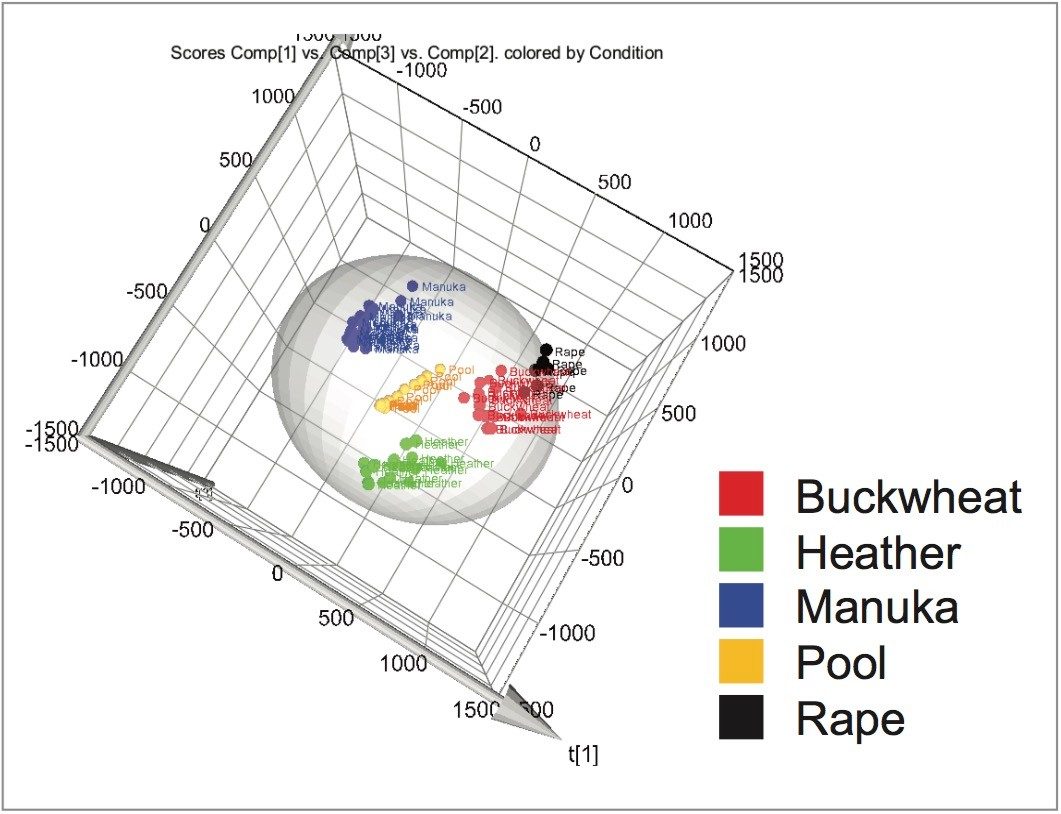
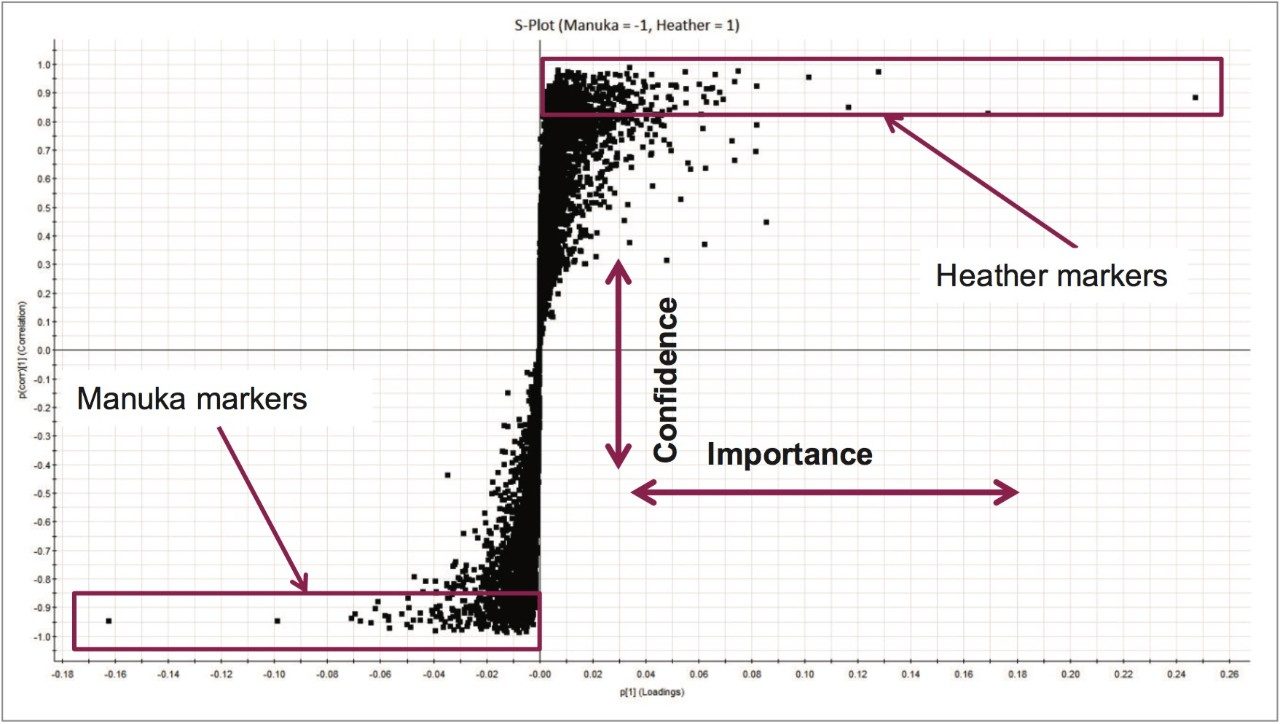
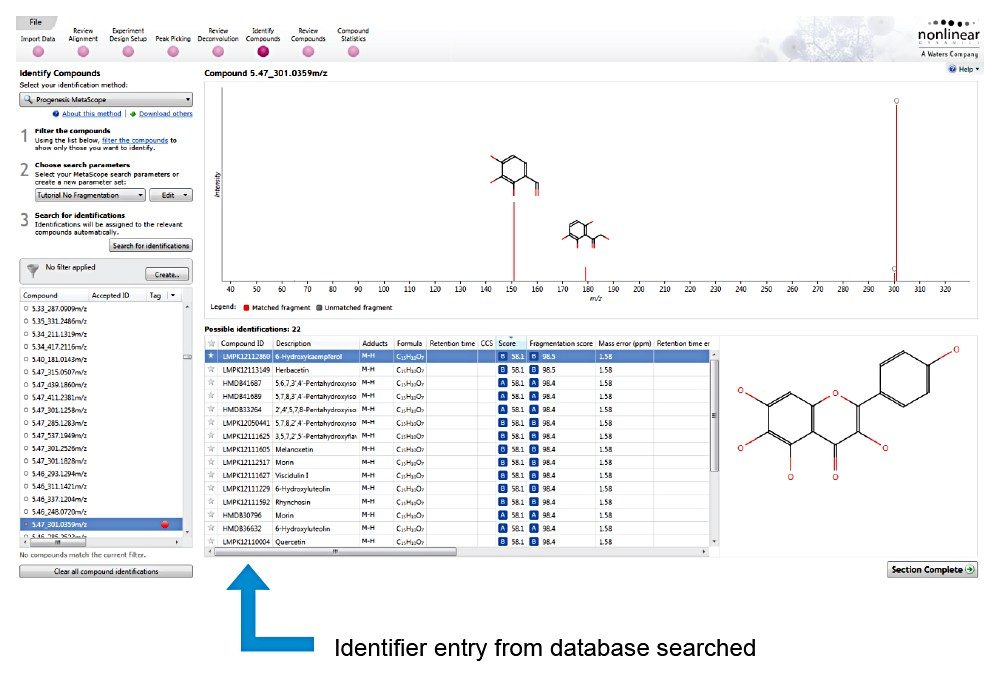
Identification of the floral origin of honey is typically achieved by melissopalynological analysis based on pollen characterization, complemented by sensory and physico-chemical analysis. However pollen identification requires a high degree of skill, in some cases gives erroneous results and can fail to detect closely related species (e.g. Manuka and Kanuka). The simultaneous detection of multiple components using spectroscopic and spectrometric techniques, coupled with statistical analysis, is a promising approach to achieve botanical discrimination.5 LC-HRMS is one technique that has been used extensively for metabolic profiling in the food and beverage industry6,7,8 including for the analysis of honey.9
In this study we investigated whether untargeted metabolomics, using Waters UltraPerformance Liquid Chromatography (UPLC) coupled with High Definition Mass Spectrometry (HDMS) and multivariate statistics, could differentiate honeys of different botanical origin. HDMS combines ion mobility spectrometry with high resolution mass spectrometry to allow researchers to analyze ions differentiated by size, shape, and charge, as well as mass. The selection of markers of different botanical origin was verified using a targeted method based upon UPLC coupled with tandem quadrupole (TQ) mass spectrometry.